 “Laaaangsam ist die Site”, haben sich die Regional Manager am Freitag bei mir beklagt. Langsam ist ein weiter Begriff. Um diese Aussage messbar zu machen, möchte ich als Ergänzung zum Nagios und Ganglia eine Messung der Antwortzeiten unserer Website einführen.
“Laaaangsam ist die Site”, haben sich die Regional Manager am Freitag bei mir beklagt. Langsam ist ein weiter Begriff. Um diese Aussage messbar zu machen, möchte ich als Ergänzung zum Nagios und Ganglia eine Messung der Antwortzeiten unserer Website einführen.
Die Integration einer derartigen Messung in Nagios oder Ganglia hat sich als schwierig erwiesen. Deshalb habe ich mich für eine “Roll-your-Own”-Lösung entschieden: Erfassung der Antwortzeiten (= Dauer eines vollständigen HTTP-Requests) mittels Curl und Cron-Job. Eintragen in ein RRD-File. Anzeige mittels rrdtool graph.
Die ersten Ergebnisse sind interessant:
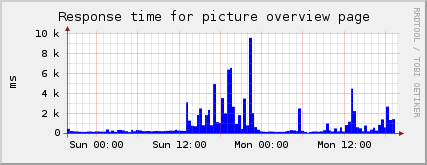
Dies ist eine Messung auf die Fotoübersichtsseite. Wenn die Server nicht belastet sind, sind die Zugriffszeiten bei <500ms. Also völlig im vertretbaren Rahmen. Schlimm wird es, sobald eine gewisse Schwelle überschritten wird. Dann explodieren die Zahlen: Gestern Sonntag dauerte es über acht Sekunden, um eine Indexseite abzurufen.
Das Verhalten, dass die Leistung beim Ueberschreiten einer gewissen Belastung zusammensackt, zeigt sich oft. Ob auf Computersystemen oder sonst in der Welt. Zum Beispiel beim Verkehr: Ende A3 Zürich-Brunau stadteinwärts. Normaler Arbeitstag im November. Von 16:00 bis 19:00 ist dort konstant stockender Kolonnenverkehr.
Oktober, Herbstferien: Etwa 10% weniger Verkehr. Aber der Verkehr rollt flüssig. Obwohl die Belastung nur marginal kleiner ist.
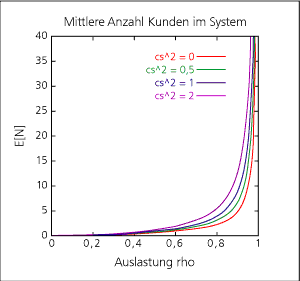
Wenn mich nicht alles täuscht, wird dies durch die Warteschlangentheorie beschrieben. Der folgende Graph stellt dieses Verhalten dar. Ab einer gewissen Belastung rho steigt die Kurve der mittleren Bedienzeit E[N] massiv an:
Auf die katastrophalen Zugriffszeiten vom Sonntag haben wir sofort reagiert: Query-Optimierung, ein dritter Master, Reduktion des seriellen Anteils. Die kritische Schwelle wird nun immer noch überschritten. Aber der Besucher muss sich nur noch maximal zwei Sekunden auf seine Fotos gedulden. Immer noch zu viel, aber für uns im vertretbaren Rahmen.
