 Pro Sekunde werden auf tilllate.com 5000 Abfragen von den Datenbank-Servern beantwortet. Wie können wir diese Last auf 30 Datenbank-Server verteilen? Mit Replikation. Aber auch nach fünf Jahren Erfahrung habe ich dieses Feature noch nicht ganz im Griff.
Pro Sekunde werden auf tilllate.com 5000 Abfragen von den Datenbank-Servern beantwortet. Wie können wir diese Last auf 30 Datenbank-Server verteilen? Mit Replikation. Aber auch nach fünf Jahren Erfahrung habe ich dieses Feature noch nicht ganz im Griff.
Auf Datenbank-Ebene besitzt tilllate.com vier Servergruppen mit unterschiedlichen Funktionen (= “horizontale Skalierung”): Werbung, Statistik, Chat und schliesslich der Rest der Website tilllate.com. Werbung, Statistik und Chat kommen mit einem einzelnen Datenbank-Server aus.
Der “Rest” macht 90% der Abfragen aus. Der Rest sind 27 MySQL Datenbank-Server. Auf diesen 27 Server befindet sich eine identische Kopie der Haupt-Datenbank. Damit dies so bleibt, muss jede Änderung der Datenbank (z.B. eine UPDATE-Query) wird über einen definierten Weg auf alle 27 Maschinen repliziert. Wir benutzen hier die Replikations-Features von MySQL.
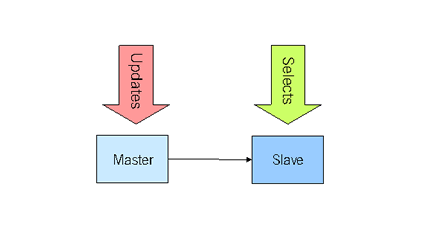
Der einfachste Fall von Replikation besteht aus einem Master-DB-Server und einem Slave-DB-Server. Der Master nimmt alle den Datenbestand verändernde Abfragen (INSERT, UPDATE, DELETE… – von nun an nenne ich diese “UPDATE”-Queries) entgegen. Der Slave holt sich beim Master alle Update-Queries und führt diese bei sich aus. Die Applikation, welche die DB verwendet sendet also alles SELECTs zum Slave. Und der Rest der Abfragen zum Master. Master und Slave haben somit immer den gleichen Zustand.
Eine App wie tilllate verursacht massiv mehr SELECT-Queries als andere Queries (Man schaut eher Fotos an, als Fotos hinzuzufügen). Wenn die Last auf unser Master/Slave-Paar nun zunimmt, kommt also zuerst der Slave-Server an den Anschlag. Man kann zur Skalierung also einem Master mehrere Slaves anhängen.
Replication-Lag
Schon bald nach der Einführung der Replikation bei tilllate traten Probleme auf: “Replication-Lag”. Normalerweise dauert es nur weniger Millisekunden, damit eine UPDATE-Query vom Master zum Slave transportiert wird. Unter Last kann diese Zeit aber auch deutlich länger sein. Von einer halben Sekunde bis – in Ausnahmefällen – mehreren Stunden.
Was hat das nun zur Folge, wenn ein tilllate-Besucher einen neuen Gästebucheintrag zu einem Member schreibt und der Replication-Lag zu gross ist? Oben im Skript wird ein UPDATE ausgeführt. Das Skript läuft weiter und nach 100ms Laufzeit folgt im selben Skript ein SELECT, welches sich alle Gästebucheinträge von der DB host. Die UPDATE-Query kommt aber erst nach 200ms beim Slave an. In diesem Fall wird der Besucher also seinen Eintrag nicht sofort sehen.
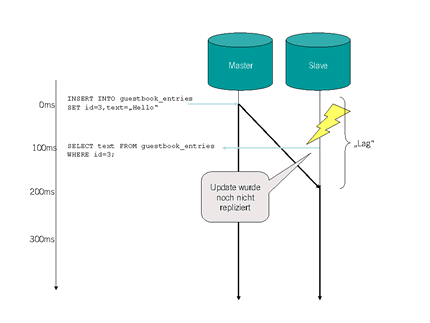
Wir umgehen dieses Problem, indem wir nach einem UPDATE die weiteren in der Seite folgenden SELECT-Queries auf den Master lenken. Dies hat aber den unschönen Effekt, dass auch eine Anzahl SELECT-Queries auf den Master gehen und dieser damit belastet wird (Hat jemand eine bessere Lösung?). Je mehr Slaves man einem Master hinzufügt, desto mehr wird dieser belastet.
Die Massnahme: Mehrere Master, welche sich gegenseitig abgleichen.
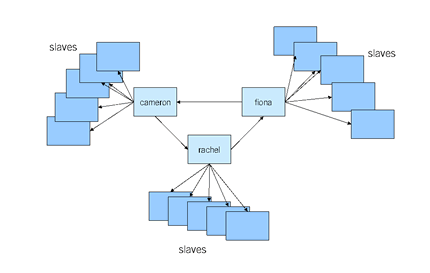
Gegenwärtig hat tilllate 3 Master-DBs, welche in einem Ring angeordnet sind. Ein Update auf fiona wird zuerst auf cameron und schliesslich auf rachel repliziert. Jeder Master hat zwischen 5 und 9 Slaves angehängt, welche sich die Updates von den Master saugen. Das Update pflanzt sich dann auf vom Master-Ring auf die Slaves fort. Bis zu vier Hops muss also ein Update reisen. Eine komplexe Angelegenheit.
Komplex = Fehleranfällig.
“Table pictures is marked as crashed. Repair it and restart slave.” meldet SHOW SLAVE STATUS – Plötzlich wird auf einem DB-Server eine Tabelle korrupt. Die Replikation zu diesem Server stoppt. Der Idealfall: Der Load-Balancer nimmt den betroffenen Server aus dem Load Balancing. Stefan oder ich kriegen ein SMS und beheben das Problem. Der Slave holt wieder auf und nach weniger Minuten ist er wieder in sync.
Schwieriger ist es, wenn ein Master des Master-Rings ausfällt. Dann werden UPDATEs von den Slaves von fiona nicht mehr zu den Slaves von cameron oder rachel weitergeleitet. Passiert dies dann noch mitten in der Nacht, haben wir unter Umständen mehrere Stunden Inkonsistenz in unserem Cluster (Wikipedia hatte schon mal 19 Stunden Replag. Von dem sind wir bisher verschont geblieben).
Probleme mit diesem Aufbau gehören denn auch zu den häufigsten Gründe für Fehlverhalten auf tilllate: Nicht sofort sichtbare Kommentare, man klickt auf den “Foto löschen”-Link, doch das Foto verschwindet erst nach einer Stunde. Verärgerte Besucher. Verärgerte Mitarbeiter.
Ich bin ratlos.
Wir sind etwas ratlos, warum Tabellen von selbst korrupt werden. Hardware-Fehler? Bugs im Mysql-Server? Bei Tabellengrössen von bis zu einem Gigabyte ist auch automatische Selbstheilung riskant. Da eine Tabellenreparatur bis zu 30 Minuten dauern kann. Und selbst REPAIR TABLE foo schafft es teilweise nicht, die Tabelle zu reparieren.
Fast 500 Datenbank-Tabellen. 5000 Abfragen in der Sekunde. 5 Jahre Erfahrung. Aber immer noch einige unbeantwortete Fragen…

11 Responses to Replikation mit MySQL: Tricky!