 Pro Sekunde werden auf tilllate.com 5000 Abfragen von den Datenbank-Servern beantwortet. Wie können wir diese Last auf 30 Datenbank-Server verteilen? Mit Replikation. Aber auch nach fünf Jahren Erfahrung habe ich dieses Feature noch nicht ganz im Griff.
Pro Sekunde werden auf tilllate.com 5000 Abfragen von den Datenbank-Servern beantwortet. Wie können wir diese Last auf 30 Datenbank-Server verteilen? Mit Replikation. Aber auch nach fünf Jahren Erfahrung habe ich dieses Feature noch nicht ganz im Griff.
Auf Datenbank-Ebene besitzt tilllate.com vier Servergruppen mit unterschiedlichen Funktionen (= “horizontale Skalierung”): Werbung, Statistik, Chat und schliesslich der Rest der Website tilllate.com. Werbung, Statistik und Chat kommen mit einem einzelnen Datenbank-Server aus.
Der “Rest” macht 90% der Abfragen aus. Der Rest sind 27 MySQL Datenbank-Server. Auf diesen 27 Server befindet sich eine identische Kopie der Haupt-Datenbank. Damit dies so bleibt, muss jede Änderung der Datenbank (z.B. eine UPDATE-Query) wird über einen definierten Weg auf alle 27 Maschinen repliziert. Wir benutzen hier die Replikations-Features von MySQL.
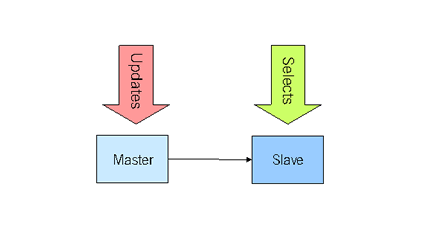
Der einfachste Fall von Replikation besteht aus einem Master-DB-Server und einem Slave-DB-Server. Der Master nimmt alle den Datenbestand verändernde Abfragen (INSERT, UPDATE, DELETE… – von nun an nenne ich diese “UPDATE”-Queries) entgegen. Der Slave holt sich beim Master alle Update-Queries und führt diese bei sich aus. Die Applikation, welche die DB verwendet sendet also alles SELECTs zum Slave. Und der Rest der Abfragen zum Master. Master und Slave haben somit immer den gleichen Zustand.
Eine App wie tilllate verursacht massiv mehr SELECT-Queries als andere Queries (Man schaut eher Fotos an, als Fotos hinzuzufügen). Wenn die Last auf unser Master/Slave-Paar nun zunimmt, kommt also zuerst der Slave-Server an den Anschlag. Man kann zur Skalierung also einem Master mehrere Slaves anhängen.
Replication-Lag
Schon bald nach der Einführung der Replikation bei tilllate traten Probleme auf: “Replication-Lag”. Normalerweise dauert es nur weniger Millisekunden, damit eine UPDATE-Query vom Master zum Slave transportiert wird. Unter Last kann diese Zeit aber auch deutlich länger sein. Von einer halben Sekunde bis – in Ausnahmefällen – mehreren Stunden.
Was hat das nun zur Folge, wenn ein tilllate-Besucher einen neuen Gästebucheintrag zu einem Member schreibt und der Replication-Lag zu gross ist? Oben im Skript wird ein UPDATE ausgeführt. Das Skript läuft weiter und nach 100ms Laufzeit folgt im selben Skript ein SELECT, welches sich alle Gästebucheinträge von der DB host. Die UPDATE-Query kommt aber erst nach 200ms beim Slave an. In diesem Fall wird der Besucher also seinen Eintrag nicht sofort sehen.
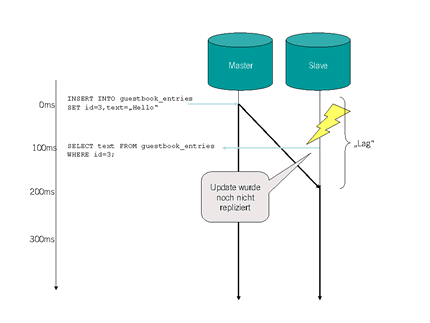
Wir umgehen dieses Problem, indem wir nach einem UPDATE die weiteren in der Seite folgenden SELECT-Queries auf den Master lenken. Dies hat aber den unschönen Effekt, dass auch eine Anzahl SELECT-Queries auf den Master gehen und dieser damit belastet wird (Hat jemand eine bessere Lösung?). Je mehr Slaves man einem Master hinzufügt, desto mehr wird dieser belastet.
Die Massnahme: Mehrere Master, welche sich gegenseitig abgleichen.
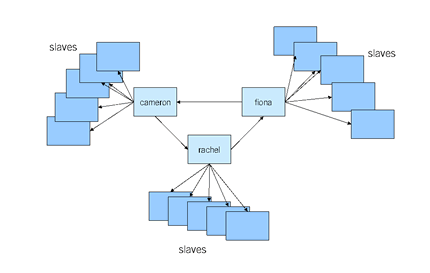
Gegenwärtig hat tilllate 3 Master-DBs, welche in einem Ring angeordnet sind. Ein Update auf fiona wird zuerst auf cameron und schliesslich auf rachel repliziert. Jeder Master hat zwischen 5 und 9 Slaves angehängt, welche sich die Updates von den Master saugen. Das Update pflanzt sich dann auf vom Master-Ring auf die Slaves fort. Bis zu vier Hops muss also ein Update reisen. Eine komplexe Angelegenheit.
Komplex = Fehleranfällig.
“Table pictures is marked as crashed. Repair it and restart slave.” meldet SHOW SLAVE STATUS – Plötzlich wird auf einem DB-Server eine Tabelle korrupt. Die Replikation zu diesem Server stoppt. Der Idealfall: Der Load-Balancer nimmt den betroffenen Server aus dem Load Balancing. Stefan oder ich kriegen ein SMS und beheben das Problem. Der Slave holt wieder auf und nach weniger Minuten ist er wieder in sync.
Schwieriger ist es, wenn ein Master des Master-Rings ausfällt. Dann werden UPDATEs von den Slaves von fiona nicht mehr zu den Slaves von cameron oder rachel weitergeleitet. Passiert dies dann noch mitten in der Nacht, haben wir unter Umständen mehrere Stunden Inkonsistenz in unserem Cluster (Wikipedia hatte schon mal 19 Stunden Replag. Von dem sind wir bisher verschont geblieben).
Probleme mit diesem Aufbau gehören denn auch zu den häufigsten Gründe für Fehlverhalten auf tilllate: Nicht sofort sichtbare Kommentare, man klickt auf den “Foto löschen”-Link, doch das Foto verschwindet erst nach einer Stunde. Verärgerte Besucher. Verärgerte Mitarbeiter.
Ich bin ratlos.
Wir sind etwas ratlos, warum Tabellen von selbst korrupt werden. Hardware-Fehler? Bugs im Mysql-Server? Bei Tabellengrössen von bis zu einem Gigabyte ist auch automatische Selbstheilung riskant. Da eine Tabellenreparatur bis zu 30 Minuten dauern kann. Und selbst REPAIR TABLE foo schafft es teilweise nicht, die Tabelle zu reparieren.
Fast 500 Datenbank-Tabellen. 5000 Abfragen in der Sekunde. 5 Jahre Erfahrung. Aber immer noch einige unbeantwortete Fragen…

Hallo tillltate-Team
Wie wäre es mit einer SAN, auf welcher die DB abgelegt wird und über verschiedene Server die Updates, rsp. Selects geleitet werden?
Theoretisch wäre das möglich und so entfällt das ewige Replizieren. Und die Performance wird auch nicht gross darunter leiden (vorallem weil die Server auch nicht mehr andauernd mit replizieren beschäftigt sind…)
Gruss
sigma
Moin Silvan,
Zwei Sachen aus der MySQL-Doku:
1.:
—
Note: For the greatest possible durability and consistency in a replication setup using InnoDB with transactions, you should use innodb_flush_log_at_trx_commit=1, sync_binlog=1, and, before MySQL 5.0.3, innodb_safe_binlog, in the master my.cnf file. (innodb_safe_binlog is not needed from 5.0.3 on.)
—
Werdet ihr wahrscheinlich bereits konfiguriert haben?
2.:
—
How do I force the master to block updates until the slave catches up?
A: Use the following procedure:
1.
On the master, execute these statements:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> SHOW MASTER STATUS;
Record the replication coordinates (the log filename and offset) from the output of the SHOW statement.
2.
On the slave, issue the following statement, where the arguments to the MASTER_POS_WAIT() function are the replication coordinate values obtained in the previous step:
mysql> SELECT MASTER_POS_WAIT(‘log_name’, log_offset);
The SELECT statement blocks until the slave reaches the specified log file and offset. At that point, the slave is in synchrony with the master and the statement returns.
3.
On the master, issue the following statement to allow the master to begin processing updates again:
mysql> UNLOCK TABLES;
—
Ist bei eurer Serverfarm wahrscheinlich eher nicht möglich 😉
Grüße,
Schakko – http://wap.ecw.de
Dein Problem liegt eindeutig daran dass du zuviele Queries in der Sekunde hast. (Sprich schlampig programmiert). Ich würde mal sagen im Schnitt solltest du pro Seitenaufruf nicht mehr als 1 Update und 1 Query haben. Den Rest der Seiten solltest du im Speicher cachen, und periodisch mit der Datenbank abgleichen. Sollte der Server crashen, gehen ein paar Daten verloren. Aber wer wann wo zuletzt auf welcher Seite war, ist ja nicht so wichtig, falls es mal verloren ginge. Für Auskünfte später hat man ja immer noch die Server log.
Wenn man liest dass du früher die anderen Sprachen Wort per Wort aus der Datenbank abgefragt hast (und das bei jeder Seite), dann bekomme ich graue Haare :).
Mein Tipp wär der Folgende: Nehmt euch einen Diplominformatiker ins Team der etwas von Algorithmen und Datenstrukturen versteht, und die Seite etwas umkrempeln kann, und versucht nicht selbst mit reinzureden ;).
Den Artikel über die Slow queries fand ich hingegen sehr gut! 🙂
@Leo:
Ring-Architektur: Dies wird z.B. hier beschrieben.
Tipp 1: Danke für den Tipp. Hier wird einfach der Code weniger schön: Der eine Teil der Daten kommt aus dem REQUEST, der Rest aus dem DB. Das ist unschöne Fallunterscheidung. Vielleicht lässt sich dies aber schlau kapseln.
Tipp 2: Du denkst an Aufteilung in 2 unabhängige Funktionsblöcke mit eigenen DB-CLuster? Wie ebay das z.B. macht. Ja, das tönt schlau. Wir müssen mal schauen, wo wir den Schnitt machen. Diese beiden Blöcke müssten eben weitgehend unabhängig sein.
@Schakko
Danke für die Tipps…
Tipp 1: Wir brauchen hauptsächlich MyISAM-Tabellen (Hier steht irgendwo warum). Somit ist dies für die meisten Tabellen leider nicht anwendbar.
Tipp 2: Diese Verfahren kenne ich. Aber die Folge sind Table Locks -> hängende Apache-Prozesse -> Alle Slots belegt -> “Seite kann nicht angezeigt werden”. Den Slave aus dem Load Balancing zu nehmen, finde ich eine bessere Alternative.
@Ich:
Welche Erfahrung kannst Du denn vorweisen, dass Du die Probleme in unserem Code und unserer Firma so eindeutig siehst?
Und bitte gib mir bitte beim nächsten Kommentar Deine E-Mail an. In diesem Blog kommentieren wir ehrlich und offen. Wir sind ja nicht feige und können zu unseren Kommentaren stehen. Wir haben ja nichts zu verbergen.
Eigentlich ein Interesantes DB Konzept.
Ich würde euer Problem auch genau so angehen wie Leo und “Ich” es beschrieben haben. (Btw:ich bin nicht “Ich” 😉 )
1. Splitten der DB in Unterbereiche.
Z.Bsp. fiona=Chat, rachel=Bilder usw.
so kommt man zwar um eine Replikation der Daten nicht herum, kann diese aber euf ein paar wenige Tabellen minimieren. Die Usertabelle wird zum Beispiel sicher auf allen Servern benötigt. Was aber wenn der User sich ganz frisch angemeldet hat und loschatten will, die Daten aber noch nicht auf den Chat server repliziert worden sind ? Hier müsste man dann halt einen Failover programmieren, dass eine 2te Query auf den Master.user Server zurückgreift.
2. Zauberwort Caching. Und da vermute ich hat tillate noch ein riesen Potenzial.
Jede Seite wird je nach der Häufigkeit der Ändereungen die Seite erfährt in eine Kategorie eingegliedert. Seiten welche nur wenig oder gar keine Dynamik erleben, würde ich direkt als HTML ablegen. (Impressum usw.)
Seiten die zwar Änderungen erfahren, aber nicht von den Usern selber, sondern von euerem “Content-Team” bearbeitet werden, reicht es meistens wenn der Update alle 5 Minuten neu im Cache abgelegt wird. Während diesen 5 Minuten hätte die Seite zum Beispeil 5000 queries gebraucht. Da sie aber gecached ist braucht es nur 1 zum ablegen. Das verhältniss ist also 5000:1. die Anzahl der Queries wird drastisch minimiert.
Den Chat würde ich in ein dafür vorgesehenes Protokoll migrieren. Irc, Jabber usw. Mit einem Flash Frontend läuft das wunderbar und performant.
Nun könnte man sich ja fragen was die minimierung des Loads mit eurem Cluster zu tun hat. nunja, je kleiner der Load, desto kleiner der Cluster und desto weniger kompliziert wird Punkt 1 😉
Just my 2c….
Hier gibt’s noch Tipps von Profis zum Thema “Replication Lag”.
Wir haben zwar nicht ganz so einen grossen MySQL-Cluster (sind bloss 7 Rechner), aber ich durfte dort auch schon einige Erfahrungen mit der MySQL-Replikation sammeln. Ich hatte jedoch stehts nur Probleme mit der Zirkel-Replikation (das was Eure fiona, cameron und rachel machen). Warum benutzt Ihr nicht eine 3-tier-Konfiguration zur Lastverteilung?
Das Problem bei nur einem Master ist ja, dass der ganz alleine alle Writes und die Replikationen zu seinen Slaves bewältigen muss. Also einfach noch eine Zwischenschicht mit Master/Slave-Servern (im Fachjargon auch als Bastard bezeichnet ;-). Hier mal am Beispiel wie wir unsere swebflex- und Mail-Server betreiben:
* Master
* Bastard1
* Slave1
* Slave2
* Slave3
* Bastard2
* Slave4
Dabei steht der Bastard2 an einer Zweitlocation. Gelesen wird nur von den Slaves, geschrieben nur auf den Master. Dieser Aufbau
Ich vermute, der Grund warum Ihr das nicht macht, ist schlicht der hohe Schreibtraffic. In unserem Fall ist der Master eine vier Prozessorige Xeon-Kiste mit mehreren GB RAM, einem 6 Platten SCSI-RAID-5-Storage und einem vernünftigen Betriebssystem.
Hallo tillate Team,
ist zwar schon einige Zeit her, aber betreibt ihr immer noch diese Konfiguration? Seit ihr mittlerweile zufrieden?
Ab 5.1 wird ja angeblich solangsam mysql-cluster interessant.
(Ich selbst bin grad an einer simplen Master-Slave Konfiguration, überlege aber evtl auf mysql-cluster umzusteigen) (Wenn das überhaupt mit unserer Applikation klappt)
Ich kenne die Komplexität und Hintergründe eurer Queries nicht, aber als ich eueren Artikel lass, war ich schon erstmal “baff”.
Für 5000 Queries auf 500 verschiedene Tabellen ist eure Serveranzahl gewaltig.
Wir betreiben auch eine Community und haben einen peak von 2900 Queries (WRITE / READ = 68% zu 32%) und 360 Tabellen.
Ich bin bis jetzt mit einem mysqlserver ausgekommen. Der slave wurde nur für backups benutzt.
(Master-Server ist ein Itanium2 4 Wege-System mit einem 14 Platten RAID10 Array, beides IBM)
Gruß Jens